MSA: retrieving thought, not text
May 20, 2026
There are three ways to give an LLM memory. All three are broken.
Fine-tune the weights? High precision, but fixed capacity and catastrophic forgetting.
External retrieval (RAG)? Scales to any corpus, but retrieves in text/embedding space, not the space the model actually thinks in. There’s a structural ceiling no amount of reranking can close.
Compress into a latent state? Efficient, but fixed-size states forget at scale. RWKV drops from 100% to 53% accuracy at 1M tokens on needle-in-a-haystack.
I’ve been exploring all three for Sketch’s memory layer. None of them fully solve the problem. Which is why this paper caught my attention.
Memory Sparse Attention (MSA), from Evermind.
Instead of retrieving text chunks from an external database, MSA retrieves the model’s own internal representations. Learned “Router Projectors” inside the transformer score documents by their KV cache signatures, select the top-k most relevant, and feed only those into attention. Retrieval and generation share the same forward pass, same loss function, same representation space.
RAG retrieves text. MSA retrieves thought.
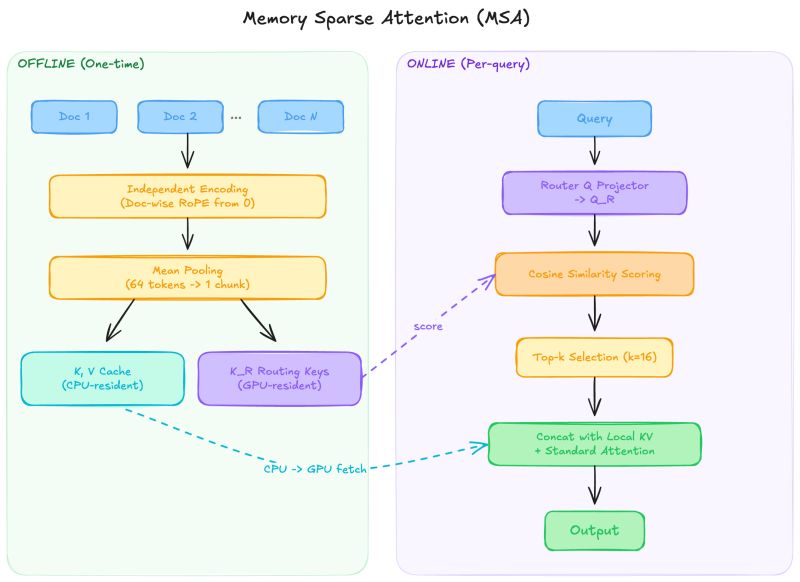
Document-wise RoPE. Each document gets independent position IDs starting from 0, decoupling positional encoding from corpus size. Train on 64K tokens. Infer on 100 million. The model never sees out-of-distribution positions because each document looks like a standalone input it’s seen thousands of times.
All on a 4B model, 2 A800 GPUs:
The biggest contributor isn’t the routing architecture. It’s injecting the original document text after routing. Compressed KVs find the right documents. Raw text generates the answers. MSA is a hybrid: latent routing, text generation.
They matter. Single backbone (Qwen3-4B). The memory parallelism that enables 100M tokens depends on the model being small enough to replicate per GPU. Unclear if this scales to 70B+. No confidence intervals on evaluations. Static memory bank requiring offline encoding.
RAG isn’t dead. It still wins on updateability, interpretability, and cost. But for large static knowledge bases where retrieval quality is the bottleneck, operating in the model’s native representation space closes a gap that pipeline architectures structurally cannot.
The real direction here is internalization. Retrieval moving from external pipeline into the model itself. MSA is one step. It won’t be the last.
Paper, MSA: Memory Sparse Attention (arXiv: 2603.23516)