Designing agents around the cache
April 23, 2026
I’ve spent the last couple of months deep in the mechanics and economics of token caching. Partly research for conversations that keep happening on our team. Partly trying to understand why cache hit rate, more than model choice or prompt quality, is what separates agents that run sustainably in production from ones that burn cash.
Almost every dollar you spend on a sustained agent workload goes to re-reading context the model has already seen. Every turn in an agentic loop resends the system prompt, the tool definitions, the memory context, the conversation so far. Most of that is identical to the turn before. Without caching, the provider reprocesses all of it from scratch and charges you full input price.
The January 2026 paper “Don’t Break the Cache” put numbers to this. On agentic workloads across GPT-5.2, Claude Sonnet 4.5, and Gemini 2.5 Pro, caching designed well cut input costs by 41 to 80 percent. The savings scale with prompt size: at 500 tokens the upside is modest, at 50,000 tokens they cross 80 percent.
That is a lot of money. It is also money that is surprisingly fragile. The savings only materialize when the prompt architecture is designed around caching from the start. Retrofit is possible, but painful. Every section of a cached prefix is load-bearing, and moving things around after launch invalidates more than you expect.
The design rules only started to make sense to me once I looked at the infrastructure layer. Not the math, but the shape.
When your request hits an LLM, the model processes it in two phases. The first is prefill: the model reads your entire input prompt in parallel and builds the internal state it needs to generate the first output token. For a Transformer, this means computing a Key vector and a Value vector for every token you sent. These K and V vectors are what attention uses to decide which parts of your prompt matter for the next token it generates. Prefill is compute-bound, and its cost scales roughly as O(n²) with prompt length. This is the expensive phase.
The second phase is decode: the model generates output tokens one at a time. For each new token, it only needs to pay attention to the tokens that came before. Decode is memory-bound and scales linearly. For most agent workloads, it is the smaller part of the bill.
Two properties of attention matter for caching. First, attention in these models is causal: a token at position N can only attend to tokens at positions 0 through N minus 1. Second, the K and V vectors for a given token depend only on the tokens that came before it. Together, something specific falls out: if the first thousand tokens of your prompt are identical to the first thousand tokens of a prompt the model processed ten seconds ago, the K and V vectors for those thousand tokens are identical too. They are deterministic functions of the input.
So instead of recomputing them, the provider caches them. That is the KV cache. Each cached KV block is indexed by a cryptographic hash of the token sequence that produced it. When a new request arrives, the provider hashes the incoming prefix block by block, looks up cached state for any prefix that matches, and skips the prefill work for that portion. This is what “a cached read is 90 percent cheaper” actually means. The attention compute on those tokens has already been done and is not billed again.
In practice, providers hash in fixed-size blocks. vLLM’s PagedAttention, which is the open-source blueprint much of this industry has adopted, uses 16-token blocks by default. Each block’s hash chains from the parent block’s hash, so the hash of block N depends on block N minus 1 all the way back to the start of the prompt. This is what allows an O(1) lookup to validate an entire multi-thousand-token prefix. One hash match, whole prefix reused.
It also explains the single most important property of caching: any change anywhere in the prefix invalidates every block after it. If the system prompt changes from “you are a senior software engineer” to “you are a Senior Software Engineer,” the hash of the first block changes, which changes the hash of every block downstream, which throws out the entire cached prefix. Even if the next ten thousand tokens are unchanged.
This is not a quirk. It is a direct consequence of the chained hash structure. Once this clicked for me, the design rules stopped feeling arbitrary. The ordering that emerges is stable at the top, volatile at the bottom, with nothing above the current writing cursor available for change.
Everything about caching comes down to one idea: static content at the top of the prompt, dynamic content at the bottom, and the prefix must match across requests for the cache to hit.
The cache hierarchy inside a well-structured agent prompt looks roughly like this, from most stable to most volatile:
Each layer sits on top of the one above it in the prompt. The first four are essentially cache-friendly. The fifth grows but appends rather than mutates, so the older parts stay cacheable.
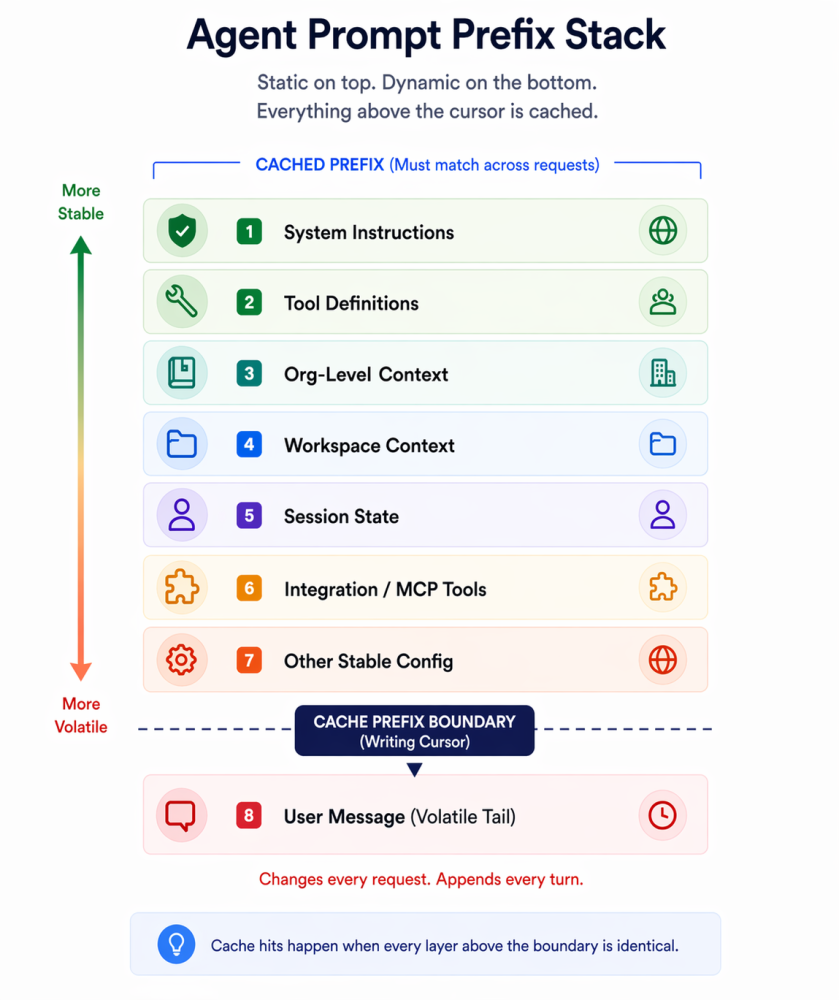
The reason this ordering is mandatory, not suggested, falls directly out of the chained hash structure from the previous section. A cache hit needs the entire prefix up to the cached block to match. If a dynamic element shows up early in the prompt, a timestamp or a user name or a session ID injected into the system prompt, then every block below it rehashes on every request. Hit rate collapses to zero. Not because the dynamic content itself is expensive, but because it invalidates everything downstream.
The experimental evidence on this is stark. Ankit Ko ran a controlled test on Azure OpenAI’s GPT-4.1-mini: one configuration with a stable prefix, one with a perturbed prefix where small elements shifted between requests. The stable prefix averaged 2,258 ms time-to-first-token with an 85.2 percent cache hit rate at $0.0096 per request. The perturbed prefix averaged 3,714 ms, a 0 percent hit rate, and $0.033 per request. A 71 percent cost reduction and a 39 to 65 percent latency improvement, statistically significant at p less than 0.000001. Same model, same content, different ordering.
The design patterns that follow from the rule are narrow:

Rules like this are simple to state and hard to maintain. Agent systems violate them constantly, often without anyone noticing.
The rule is simple. The violations are not, because most of them are invisible. Cache hit rate does not raise an exception when it drops. It just shows up in the next bill. Five patterns account for most of the damage we’ve seen across our own systems and in case studies from teams shipping agents to production.
Timestamps and dates in the system prompt. The most common killer. Someone adds The current date is ${new Date()} to the system prompt because the model needs to know what day it is. Every request now has a unique hash for block one. The cache hit rate for that field onwards is zero. The fix is to move time into the user message or a block at the volatile tail, and if time accuracy matters for the whole session, freeze it once per task rather than updating per turn.
Non-deterministic JSON serialization of tool definitions. Most JSON serializers do not guarantee key ordering. If the tool schema sometimes serializes as {"name": ..., "description": ...} and sometimes as {"description": ..., "name": ...}, those are different token sequences, different hashes, no cache hit. json.dumps(data, sort_keys=True) on the Python side or a deterministic serializer on the TypeScript side fixes this in one line. This is easy to miss for months, because the hit rate drops gradually and nothing in the API surface flags inconsistent serialization.
Capitalization and whitespace changes. One documented case: a 2,727-token cached prefix evaporated when “senior software engineer” became “Senior Software Engineer.” The hash of the first block changes, the chain downstream rehashes, the cache is gone. Template consistency matters. Prompt builders that auto-apply title case or smart quotes can silently destroy hit rate.
Mid-session tool changes. Adding a new tool, removing one, updating a parameter schema, or reordering the tool list all invalidate the prefix. This is the logic behind keeping every tool loaded at all times, even ones that seem situational, and implementing state changes as tool messages rather than tool-set swaps. Conditional behavior belongs inside a tool that checks state, not in a shifting tool list.
Model switching mid-session. KV caches are model-specific. Switching from Opus to Sonnet 100K tokens into a conversation does not save money. Sonnet has its own cache, empty for that prefix, and the entire context rebuilds from zero. The net effect is often a more expensive request, not a cheaper one. The subagent pattern, where a main agent prepares a focused handoff for a cheaper model with its own small context, is the correct answer.
A common misconception: temperature and top_p do not invalidate the cache. These parameters act after the attention mechanism, so they do not affect the K/V vectors that get cached. Sampling parameters can vary freely between requests without losing the prefix.
The pattern across all of these: the damage happens silently, the signal is in the bill, and the fix is almost always trivial once you know to look for it. Knowing to look for it is the skill.
Claude Code is the most cache-aware agent I know of running at scale. A 92 percent cache hit rate across their sessions, an 81 percent cost reduction relative to uncached operation, and an entire harness engineered around the prefix-match constraint. They treat cache hit rate as a first-class production metric. Alerts fire when it drops. SEVs get declared when it drops sharply.
Three operating rules fall out of their architecture, each a direct response to a way the cache silently breaks in practice:
Models don’t get swapped mid-session. If a conversation is 100K tokens deep on Opus and a simpler question could be routed to Sonnet, Sonnet’s separate cache has to rebuild the entire prefix. The apparent savings evaporate in a single uncached prefill. The pattern they use instead is subagents: the main model prepares a focused handoff, the cheaper model works from a small context of its own, and the main cache stays warm.
Tools don’t get added or removed mid-session. Tool definitions are part of the cached prefix. Plan mode, which a direct implementation would handle by swapping the tool set to read-only, is instead implemented as a tool message. Every tool is always loaded. Entering and exiting plan mode are themselves tools. The prefix never changes shape, only the state inside it does.
The prefix doesn’t get mutated to update state. State updates go through append-only messages in the user turn, never through edits to the system prompt or tool list. The prefix is treated as write-once per session.
What makes the architecture distinctive is not the rules themselves but the infrastructure around them. Consider something as mundane as how CLAUDE.md and the current date reach the model. They do not live in the system prompt. The harness wraps this content in a tag and prepends it as a synthetic first message in the conversation array on every API call. The content is memoized per session, so it stays byte-identical across turns and occupies a stable slot at the top of the cached prefix. The date inside that message is deliberately left stale after midnight rather than refreshed, because refreshing would invalidate the prefix and force a cache re-creation on the next turn. On an overnight session with a large context, that one refresh would cost something like 920K tokens in cache writes. The cheaper behavior is to lie about the current time.
Claude Code also has PreCompact and PostCompact lifecycle hooks, first-class events that fire when context compaction is about to happen or has just happened. They let the harness make cache-aware decisions at exactly the moments when the prefix is most vulnerable to invalidation. Compaction, which summarizes older turns into a shorter form, is one of the most cache-hostile things an agent can do. Hooking the lifecycle around it is how Claude Code keeps the damage contained.
The underlying philosophy is that cache layout is not a thing the harness does quietly in the background. It is a thing the harness is actively responsible for and instrumented around. The alternative is to treat caching as a side effect of provider behavior, something that happens quietly underneath. Claude Code treats it as a product surface.
Four providers, four different answers to the same question: how much of the cache surface should the developer have to think about? The answer each one picks reveals how they think about agents more broadly.
Anthropic: explicit control. Caching requires marking cache_control on specific content blocks. Up to four breakpoints per request, minimum 1,024 tokens per checkpoint. TTL is five minutes by default, one hour for extended caches with a 2x write premium. On Sonnet 4.6, the math works out to $3.00 per million input tokens normally, $0.30 per million on cache reads, $3.75 per million on cache writes. Break-even lands at about 1.4 cache hits per cached prefix. The philosophy is explicit: you tell the provider what to cache, you own the architecture, the discount is a reward for getting the layout right.
OpenAI: fully automatic. No flags, no code changes, no breakpoints. Prompts above 1,024 tokens get hashed and routed to cached state when a match is found. Roughly 90 percent discount on cache reads on GPT-5.4, free writes, five-to-ten-minute inactivity TTL (up to 24 hours on the gpt-5.x line with extended retention). The philosophy is automatic: the provider handles cache routing, the developer focuses on everything else, and the price of that simplicity is a smaller surface for tuning when things go wrong.
Google (Gemini): hybrid. Implicit caching is automatic and gives a 75 percent discount. Explicit caching, through named cache objects, gives 90 percent but requires creating and managing a cache resource with its own TTL (60 minutes default) and storage fee ($4.50 per million tokens per hour). Minimum cache size is higher than the other two: 2,048 tokens for Flash, 4,096 for Pro. The named-cache primitive is unique and genuinely useful when the same large context is reused across many users. The philosophy is hedged: automatic for the common case, explicit for the careful case, with storage billed separately.
Moonshot (Kimi): distributed infrastructure. Automatic context caching with a 75 percent discount on hits. Storage billed per minute, similar to Google’s model. What is architecturally distinctive is that Moonshot published the infrastructure: MOONCAKE, a distributed KV cache pool shared across inference nodes. In their own benchmarks, MOONCAKE achieves a 2.36x higher cache hit rate than a local per-node cache and cuts prefill compute by up to 48 percent. The philosophy, visible in the fact that they wrote a paper on it, is that caching is a distributed systems problem worth solving at the infrastructure layer, not a prompt design problem for the developer.
A fifth option: self-host with an open model. Kimi K2.6, released in April, is open-source under a Modified MIT license, which means the model and its inference stack can run on your own infrastructure. Projects like vLLM’s PagedAttention and SGLang’s RadixAttention handle prefix caching at the runtime layer with automatic hit detection, per-tenant isolation, and no per-minute storage fees because the cache sits on your own GPUs. The philosophy is ownership: control the whole stack, pay for the hardware instead of the API, and treat cache as a capacity problem instead of a pricing problem.
If you are building serious agents, the explicit models (Anthropic, or self-hosted with a runtime that gives you primitives) align better with the architectural thinking the work actually demands. Caching well is largely about choosing where the prefix boundary sits, which parts of context freeze at what lifecycle, and how state updates get appended without mutation. Those are design decisions, not operational tuning. A provider that forces you to think about them is a provider that has agreed with you about what the work is. A provider that hides them is a provider that thinks the work is somewhere else.
Sketch is an org-level AI assistant that runs on Slack and WhatsApp. Multiple users per organization, shared memory and skills across users, separate threads and channels, scheduled tasks. It runs on Anthropic’s explicit caching model via the Claude Agent SDK, which means the prompt architecture had to be designed around breakpoints from the start. Getting this right is not a matter of tuning. It is a matter of where every piece of content sits in the prompt.
Sketch does not use the SDK’s preset system prompts. The Claude Code harness defaults are replaced entirely. The system prompt is a plain string produced by Sketch code, and the rest of the prefix is assembled by the SDK from files in known locations on disk.
The layer stack. The cached prefix ends up with several distinct layers, each with its own scope:
~/.claude/skills/.Only after all of this does the user message arrive, carrying the volatile block and the actual message text. Two users in the same org on the same platform share layers 1 through 3 and 6 through 7, while differing in the workspace layers.
CLAUDE.md as short-term memory. The workspace CLAUDE.md is Sketch’s writable memory store. When a user says “remember that I prefer metric units” or the agent notices something worth keeping, it writes to workspace CLAUDE.md using the built-in Write and Edit tools. There is no special Sketch code managing this. The system prompt instructs the agent about memory behavior, and the tag in the user-message block tells the agent exactly where the file lives.
The SDK does not put CLAUDE.md in the system prompt. Internally, it runs a Claude Code subprocess that wraps CLAUDE.md content in a tag and prepends it as a synthetic first message in the conversation array on every API call. The content is memoized per session, so it stays byte-identical across turns and occupies a stable position at the top of the cached prefix. Two users in the same org get different content in this slot, their respective workspace CLAUDE.md files, which is why memory stays isolated even though the org-level layers of the prefix are shared.
Structurally, this means the cached prefix spans two fields of the API payload. Sketch’s custom system prompt lives in the system: field. CLAUDE.md content lives in messages[0] as a synthetic user message with isMeta: true. The layer stack above is the semantic view. The payload structure is split across two places but caches as one continuous prefix.
Layer 1 in detail. The system prompt contains only org-level configuration. The bot’s name, the org’s name, and a set of sections that are static per platform. It changes only when an admin updates org settings, which is rare. Crucially, it contains zero per-user content. No names, no email addresses, no workspace paths, no timestamps, no request-specific data. Two users in the same organization, on the same platform, see identical system prompt strings. There is a test that validates the section ordering, because a well-meaning refactor that reorders them would invalidate the cache for every user on the next deploy.
One of those sections, the Context Protocol section, documents every sub-tag the agent might see in a user message. That documentation sits in the cached prefix, so the agent’s understanding of the volatile context format is itself cached. Dynamic content in the tail of the user message can change freely without the agent losing its interpretive framework.
In v0.18.0, we replaced the default Claude Code preset with this custom system prompt, specifically for cache efficiency. The preset carried assumptions appropriate for a coding harness but not for a multi-tenant chat assistant, including content that would have caused per-user variation inside the stable section.
Layer 2 in detail. Everything volatile goes in the user message. The block wraps the user’s actual message and looks something like this:
<context>
<time> Monday, April 21, 2026, 8:45 PM </time>
<workspace> /data/workspaces/user-abc123, org: /data/orgs/acme-corp </workspace>
<user> Name: Roopak Nijhara, Email: roopak@canvasx.ai </user>
<thread> [2026-04-21 20:43] Alice: What's the status on Q2 planning? </thread>
</context>
What's our deadline looking like?There is a comment next to this code that captures the intent: “Keeping dynamic context in the user message (not system prompt) avoids invalidating the SDK session cache on every request.” That is the central move.
The context slots are ordered by stability. The workspace path changes per-user but rarely per-request. The time tag changes every request. The thread buffer updates whenever a new message arrives in a Slack thread.
One detail that took us time to get right: the time tag. Originally its format was locale-dependent, which meant the same UTC moment could render differently depending on the host environment. Two servers handling the same request would produce different token sequences. We pinned the formatter to an explicit en-US locale in v0.19.0 to get byte stability. It is the kind of thing that invisibly costs you 10 to 20 percent of your cache hit rate and is nearly impossible to spot from cost dashboards alone.
Session scoping. The Claude Agent SDK’s resume parameter enables prefix caching across requests, but only when the session ID matches. Sketch scopes sessions by conversational unit: all DMs with a user share one session, each Slack thread gets its own, each WhatsApp group gets its own, scheduled tasks run fresh with no resume. Reusing a session across conceptually distinct conversations would keep the cache warm but pollute context.
Metrics. Every agent request emits cacheReadTokens and cacheCreationTokens as OpenTelemetry span attributes, and cost per request is computed with cache tokens factored in. We override PostHog’s default cost calculation because it ignores cache tokens and would otherwise overstate our spend. Without this instrumentation, we would not know when a new deploy silently regressed hit rate.
What matters more than any single design choice is that every layer of the prefix caches at its natural scope, and all per-request variation lives in the tail of the user message. Once that invariant is maintained, the cache takes care of itself.
The temptation when building an agent is to ship the product first and worry about cost later. This works for many things. It does not work for caching. By the time the bill shows up, the system prompt has a timestamp in it, tools get hot-swapped based on user state, CLAUDE.md gets mutated in place, and there are fifteen places where dynamic content leaks into what should be the stable prefix. Each fix is small. Together they are a rewrite.
The specific work that caching requires is not hidden. It is the ordering of the prompt. The boundary between stable and volatile content. Whether tool definitions are deterministic. Whether session scope matches conversational scope. Whether memory writes go to a file that caches at the right layer. Whether metrics reveal when any of this regresses.
These are decisions, and they get more expensive to change the further into production an agent goes. The payoff for making them early is 40 to 80 percent of the input cost of running the agent, compounding every turn it runs. That is what makes cache layout an architectural choice rather than an operational one.